

What is Data Modeling?
The business value isn't in your data, it lies in the transformation and modeling layer

Today, every company gathers data and aims to use it effectively. The problem is, raw data doesn't lead to valuable insights or predictions because it's not structured for data analytics. Data transformation is a crucial step in ETL/ELT (Extract - Load - Transform) processes, which are common data integration techniques. In this article, we'll delve into the transformation process and clarify the data modeling landscape.
What is data transformation?
Simply put, data transformation is the process of changing the format, structure, or values of your variables. The aim of structuring and reformatting data is to transform it into a data model from which you can learn insights and derive business intelligence.
Often, the transformation step includes merging transactional data with operational data to make it useful for business analytics and BI. For instance, a transformation platform might combine name, location, and pricing data from business operations with transactional data like retail sales or healthcare claims, based on the structure needed for data analysis. Transformations are mainly driven by the unique needs of analysts looking to address a specific business issue using data.
There are various advantages to transforming data:
✅ Better organization: Transformed data is easier to process for both people and computers.
✅ Data quality: Raw data usually has low quality: missing values, empty rows, and poorly formatted variables. Transforming data to enhance its quality makes life easier for data users, helping them be more productive and gain better insights from their data.
✅ Usability: Too many organizations sit on a bunch of unusable, unanalyzed data. Standardizing data and organizing it properly enables your data team to create business value from it.
The data transformation workflow
- Data discovery and profiling: The first step in the transformation workflow involves identifying and understanding data in its original source. This helps you decide the operations needed to reach the desired format or structure.
- Translation and mapping: This step establishes a clear connection between the source and target destination fields.
- Workflow creation: In this step, the code to execute the transformation task is written. The code is often generated using a specific data transformation platform.
- Workflow execution: Data gets converted to the desired format.
- Data review: Transformed data is examined to ensure correct formatting.
Different ways of transforming data
Data can be transformed in the following ways:
Revising
Data cleaning: For example, when a variable is altered to fit a given format.
Deduplicating: getting rid of duplicate records in the database.
Format change: This includes the replacing of incompatible characters, adjusting units/dates format. For example, changing a given variable's format from integer ('int') to double ('dbl') to correct a mistake.
Computing
Summarizing: Get aggregate variables to summarize data.
Pivoting: Turning row values into columns.
Search performance: Indexing, ordering, sorting so the data can be found easily.
Distribution: You can apply transformations to the data's distribution to uncover the insights you're looking for. For example, using a log transformation with data that have different orders of magnitude allows to put them on the same scale and go forward with your analysis.
Separating
Splitting: Split a single column/variable into multiple ones.
Filtering: Select specific rows or columns in the database.
Combining
Joining: link data together.
Merging: consolidate data from multiple sources.
Integrate: reconcile name and values for the same data element across different source
Evolution of data transformation tools
We distinguish three generations of data modeling solutions:
1st generation: Data transformations are operated by ETL (Extract-Transform-Load) tools, mostly using python and airflow.
2nd generation: EL-T (Extract-Load-transform) processes come to replace Traditional ETL. Transformations are now operated in the data warehouse. A blurry era with no tools specifically dedicated to data transformation.
3rd generation: Emergence of tools specialized for data transformation in the data warehouse. A new transformation paradigm is established with the emergence of dbt.
Data modeling 1.0: transformations in the ETL era
Before looking at first-generation transformation tools, it's worth understanding how data transformations were conducted back in the day.
Data transformation is part of the wider data integration process, which consists in integrating data from multiple sources into a single source of truth, usually the data warehouse. The point of building a unique source of truth is to allow data users to find data more easily than when it's scattered across dozens of applications and source systems.
In the 1990s, the ETL (Extract- Transform - Load) process was the most widely used approach to data integration. Getting data from multiple sources into the data warehouse involved three key steps: data was first extracted from its source system, transformed as needed, and then loaded in the data warehouse. The key thing to remember is that in the ETL process, data is transformed before being loaded in the warehouse. The reason for that is that in the 1990s, when storage and bandwidth were crazily expensive, it would have been silly to load untransformed, raw, unusable data in the data warehouse. Analysts had to define a specific data project and business use case, so that data could be transformed accordingly and then loaded in the data warehouse. Due to this, the extracting and loading steps of the ETL process were tightly coupled, and ETL pipelines were performing these two steps altogether.
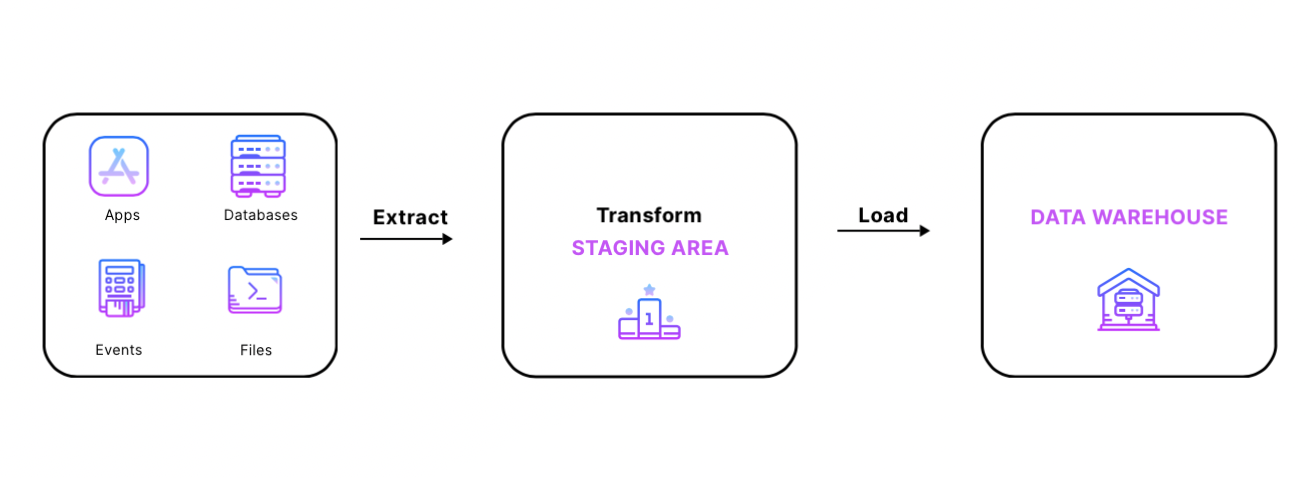
ETL pipelines were designed by data engineers and involved a lot of custom code using scripting languages such as Bash, Python, C++, and java. The tools used to transform data were the same tools that performed the extraction and loading steps of data integration: good old ETL tools.
Data modeling 2.0: data is transformed in the warehouse
In the past decades, storage and computation costs plummeted by a factor of millions, with bandwidth costs shrinking by a factor of thousands. This has led to the exponential growth of the cloud, and the arrival of cloud data warehouses such as Amazon Redshift or Google BigQuery. The peculiarity of cloud data warehouses is that they are infinitely more scalable than traditional data warehouses, with a capacity to accommodate virtually any amount of data.
These new cloud data warehouses called for a radical change in data integration processes. Now that the storage and bandwidth constraints had vanished, loading bunches of untransformed data in the cloud data warehouse wasn't a problem anymore. It meant that the transformation step could easily be completed in the cloud data warehouse after the data had been extracted and loaded. EL-T (Extract - Load - Transform) processes thus came to replace traditional ETL as the transformation layer was moved at the end of the workflow. This new approach to data integration was much more time-efficient, as data pipelines became much less complex.

This marked the entry into a rather blurry era. The transformation step was handled in the cloud data warehouse, and this was a big change. However, no standards, or rules dictating how transformations should be conducted were established. For a few years after ELT processes became commonplace, transformations were performed using SQL, python, sometimes airflow. We didn't really find a widespread, unified way of transforming data. The absence of dedicated tools for data modeling led to a lack of visibility across the cloud data warehouse. And that was a big issue. Businesses deal with thousands, even millions of datasets. With no clear transformation standard that data team can learn and apply, it quickly becomes chaos.
Data modeling 3.0: New paradigm for transformation
In 2016, dbt, a platform you've most certainly heard of, pioneered the third generation of data modeling solutions.
dbt is a platform that specifically dedicates to data transformation, focusing only on the T in the EL-T process. It's now widely accepted that dbt set a new standard for data transformation. With dbt, transformations are no longer written in complex scripting languages as under the ETL paradigm. Data modeling now happens in SQL, a language shared by BI professionals, data analysts, and data scientists. This means that transformations, which used to be exclusively owned by data engineers, can now be handled by analysts and less technical profiles. Transformations are also operated collaboratively.
dbt Labs built a community of 15,000 data folks, sharing and exchanging dbt packages and tips on how to best normalize and model data for analysis. Dbt unified how transformations were operated, giving rise to a long-awaited new paradigm. In this new paradigm, everyone who knows SQL can get their hand dirty and build transformation pipelines. Data engineers saw their role shift, increasingly focusing on the extracting and loading stages, leaving the transformation step to less technical profiles.
This had both great and not so great implications:
✅ Great
Data scientists and data analysts are much more in touch with the strategic impact of data than software engineers. It thus makes sense to put them in charge of data transformation, since they know better than anyone the ultimate goal of structuring data for a particular business purpose. Another great outcome is that data scientists and data analysts can access the raw data and do their own transformation without needing to file a ticket and wait for a data engineer to pick it up.
❌ Not so great
Data analysts are mostly driven by short-term objectives, as they work under operational constraints. Their dashboards and BI reports are expected tomorrow, not next month. They solely care about getting access to insights, and quickly. Now that they can learn to transform data without needing engineering support, they can access business insights even quicker. In practice, here's what occurs: a data analyst creates a new table for a precise use case, calls it "customer churn_2021", gets access to insights, builds a report, presents it to his manager, moves on with his day. Where does the table go? nowhere. It stays in the warehouse, with the other 200 tables bearing the same name and forgotten by other analysts.
The result? complete chaos. Obviously, tables created by analysts can only be used for a single use case, because they've been built for a single-use case. This leads to messy data warehouses, with unusable and poorly documented tables. It uselessly takes up a lot of storage and demands tremendous monitoring effort to deal with data quality issues. With the number of datasets created when everyone gets involved with data transformation, you better have a solid data documentation solution if you don't want to end up drowning in a sea of unlabelled, poorly documented data.
Data engineers transform data according to a different logic. Their objective is to build a solid data infrastructure, providing clean and reliable data for self-service analytics. Data engineers seek to transform and structure data in a way that makes it useful for business analysis, but that also makes it reusable for different use cases. Their capacity for abstraction and long-term mindset leads to well-structured data warehouses, with one table serving dozens of analysts' use cases.
Now, the sky is not all grey. We're witnessing the emergence of a new role: the analytics engineer, which remedies these issues. Analytics engineers have enough business context and experience with data tools to build reusable data models. They basically apply software engineering best practices to data analysis and bring a business-oriented mindset to data engineering efforts. When analytics engineers are in charge of data transformations, organizations live in the best possible world: great data infrastructure, well-built and reusable databases in a self-service configuration, and perfect visibility across the data warehouse.
Which transformation tool for your organization?
Below is a landscape of data transformation solutions, which can hopefully help you choose the right platform for your organization.
More modern data stack benchmarks?
Find more benchmarks and analysis on the modern data stack here. We write about all the processes involved when leveraging data assets: from the modern data stack to data teams composition, to data governance. Our blog covers the technical and the less technical aspects of creating tangible value from data. If you're a data leader and would like to discuss these topics in more depth, join the community we've created for that!
At Castor, we are building a data documentation tool for the Notion, Figma, Slack generation. Or data-wise for the Fivetran, Looker, Snowflake, DBT aficionados. We designed our catalog to be easy to use, delightful and friendly.
Want to check it out? Learn more about CastorDoc with a free demo.
Subscribe to the Castor Blog
.png)
You might also like





Get in Touch to Learn More


“[I like] The easy to use interface and the speed of finding the relevant assets that you're looking for in your database. I also really enjoy the score given to each table, [which] lets you prioritize the results of your queries by how often certain data is used.” - Michal P., Head of Data
